Vector Search in AI: How Vector Databases Are Powering Next-Gen Recommendation Engines
Paige Watson
Published on 25 March 2026Modern AI recommendation systems are no longer powered by keywords or rule-based filters. Instead, they rely on vector search—a technique that enables machines to understand semantic meaning and context at scale.
At the core of this transformation are vector databases and advanced nearest neighbor algorithms that make real-time, high-accuracy recommendations possible. This shift is especially impactful in academic systems like PeerSubmit, where accurate reviewer recommendation is critical.
What Is Vector Search (Technical View)
Vector search converts data into high-dimensional embeddings and finds similar items using distance or similarity metrics.
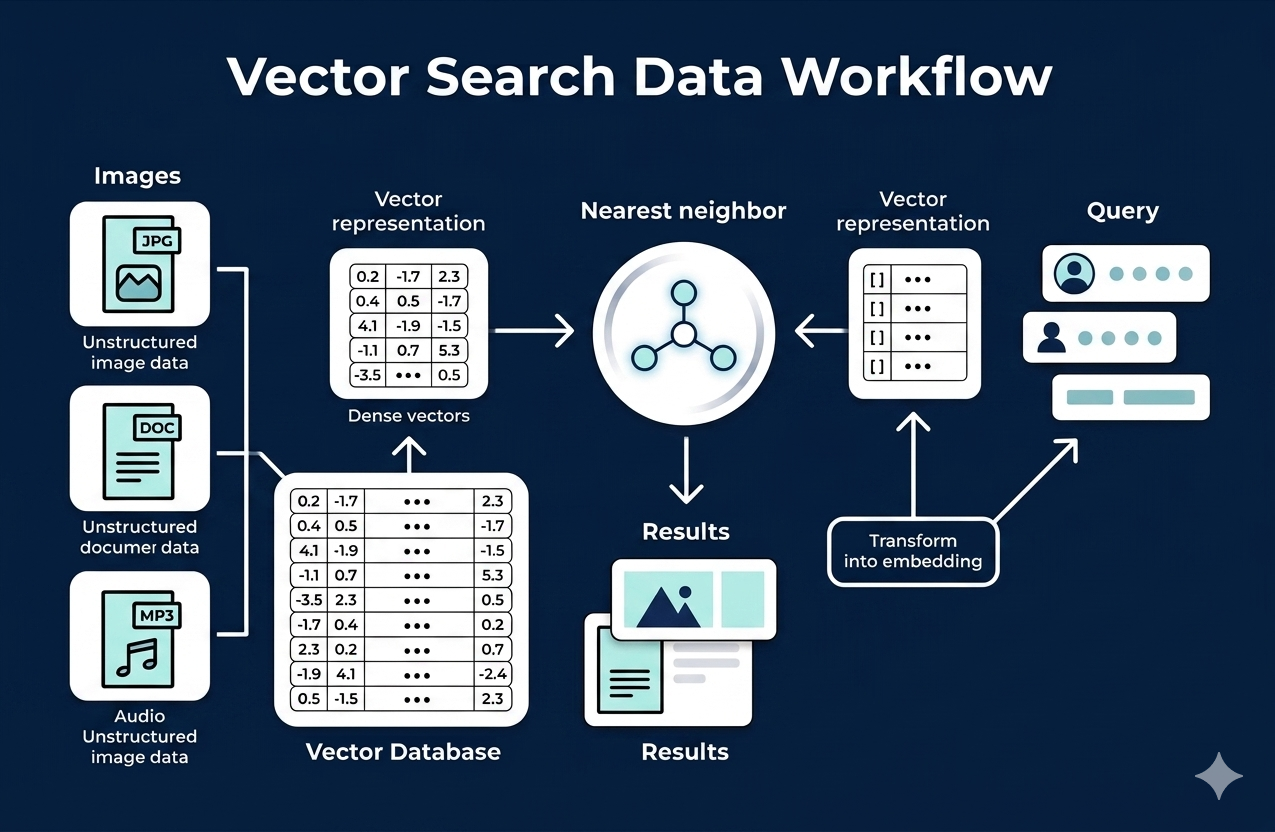
- Each paper and reviewer is represented as a vector
- Similarity is calculated using cosine similarity or dot product
- Nearest neighbor search identifies the most relevant matches
This allows systems to match based on meaning rather than exact keyword overlap.
Why Traditional Systems Fail at Scale
Keyword-based systems break down when dealing with large-scale, semantic data.
- Cannot capture semantic similarity
- Require manual tagging and filtering
- Fail with synonyms and domain variations
- Do not scale efficiently
Vector search solves these issues using mathematical similarity instead of exact matches.
Core Algorithms Behind Vector Search
Vector search relies on Approximate Nearest Neighbor (ANN) algorithms to achieve both speed and scalability.
1. HNSW (Hierarchical Navigable Small World)
HNSW is the most widely used algorithm in modern vector databases. It builds a multi-layer graph structure where higher layers enable fast navigation and lower layers provide precise search.
- Graph-based nearest neighbor search
- Logarithmic search complexity
- High accuracy and low latency
HNSW is ideal for real-time systems like recommendation engines.
2. IVF (Inverted File Index)
IVF partitions vectors into clusters and searches only the most relevant clusters during query time.
- Cluster-based indexing
- Faster search with reduced search space
Often combined with compression techniques for large-scale systems.
3. Product Quantization (PQ)
PQ compresses vectors into smaller representations, enabling efficient storage and search at scale.
- Reduces memory usage significantly
- Used for billion-scale datasets
This comes with a small trade-off in accuracy.
Which Algorithm Is Best?
Different algorithms serve different use cases, but one stands out for most applications.
- HNSW → Best for real-time, high-accuracy systems
- IVF + PQ → Best for massive-scale datasets
- PQ → Best for memory optimization
In most modern AI systems, HNSW is the default choice.
What Is a Vector Database?
A vector database is designed to store embeddings and perform fast similarity searches across large datasets.
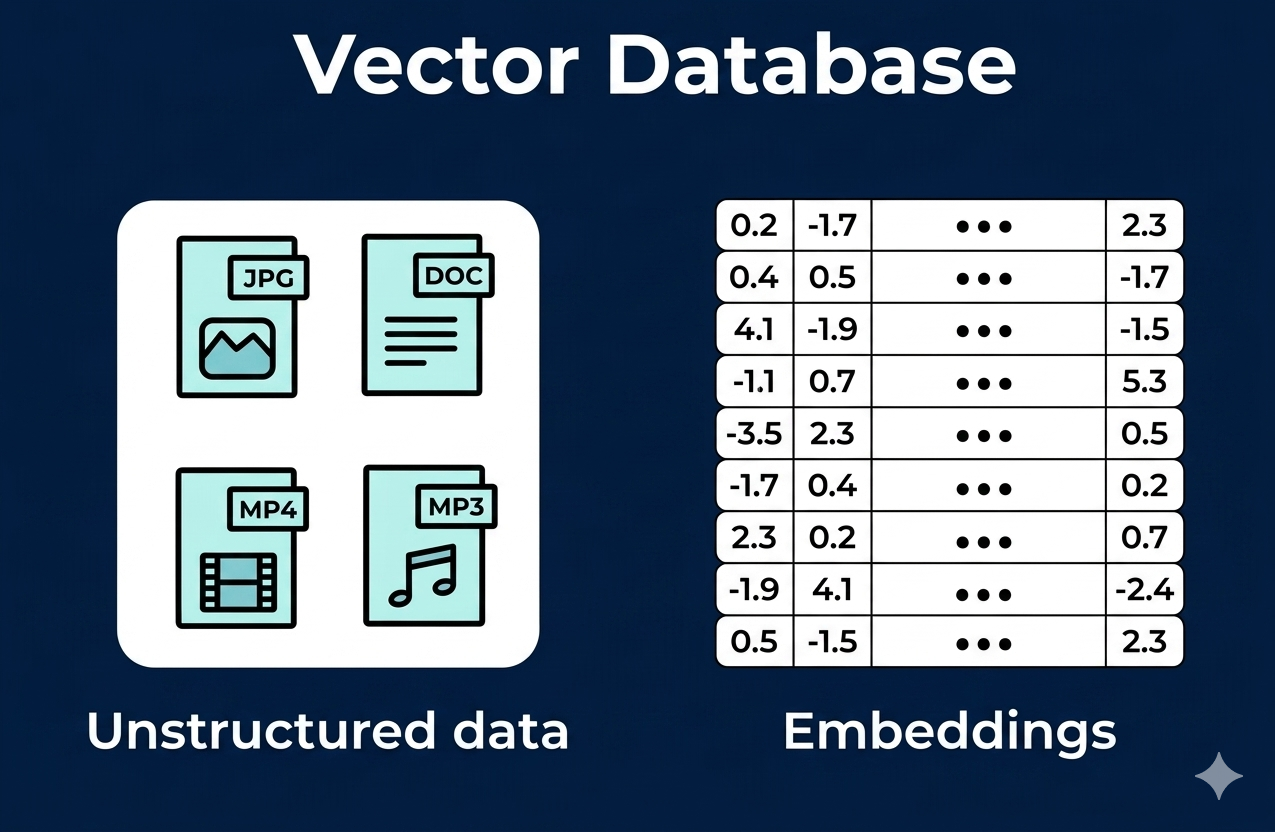
- Stores high-dimensional vectors
- Performs nearest neighbor search
- Scales to millions of data points
Popular vector databases include FAISS, Pinecone, and Weaviate.
How PeerSubmit Uses Vector Search (Technical Implementation)
PeerSubmit uses vector search to power its AI reviewer recommendation system, ensuring accurate and scalable matching between papers and reviewers.
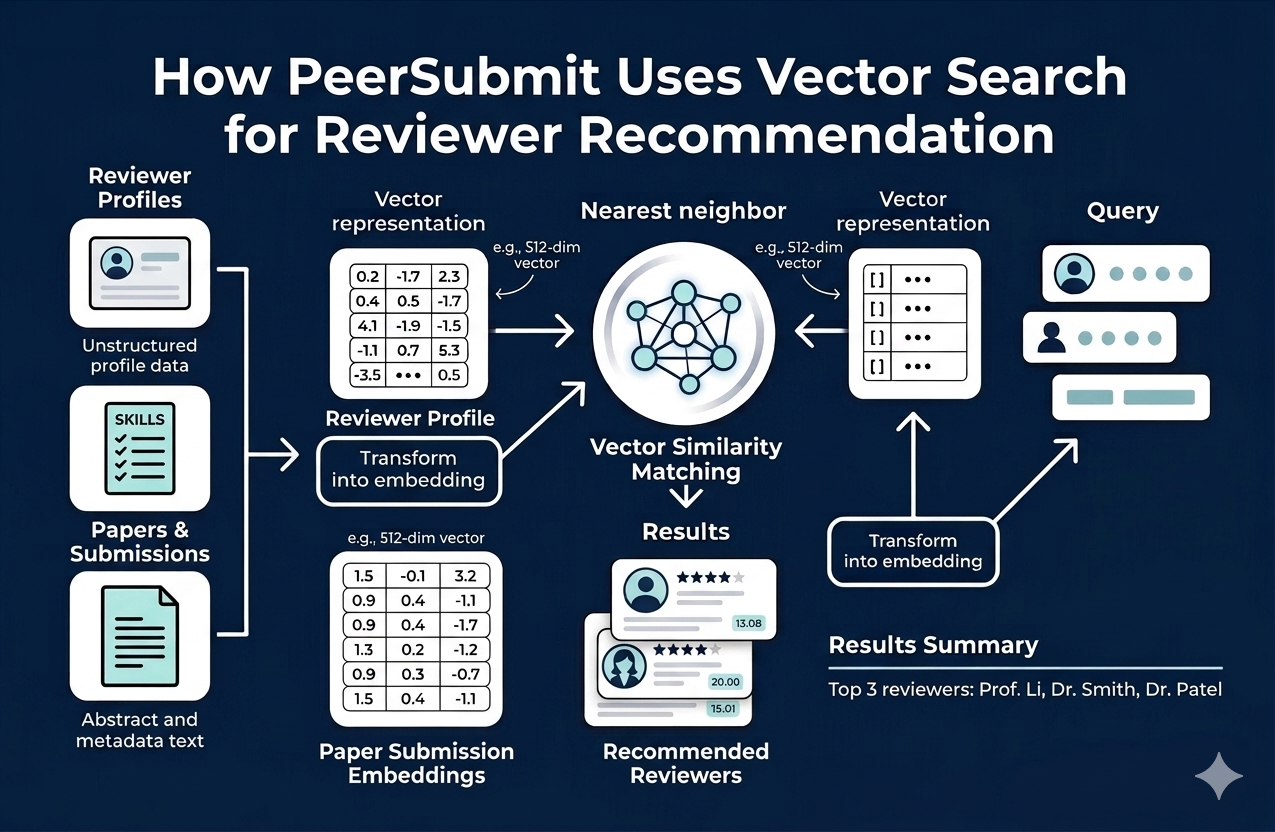
Step 1: Embedding Generation
- Paper title, abstract, and keywords are converted into embeddings
- Reviewer expertise and publications are converted into embeddings
Step 2: Vector Indexing (HNSW)
PeerSubmit uses HNSW-based indexing to store reviewer vectors efficiently and enable fast similarity search.
- Graph-based index for fast navigation
- Supports dynamic updates (new reviewers, new papers)
Step 3: Similarity Search
- Query vector (paper) is compared against reviewer vectors
- Top-K nearest neighbors are retrieved
Step 4: Ranking and Filtering
- Results ranked by cosine similarity
- Additional filters applied (conflict of interest, availability)
This pipeline ensures high accuracy, low latency, and scalability for large academic conferences.
Advantages of Vector-Based Recommendation
- Semantic understanding instead of keyword matching
- Real-time recommendation capability
- Scalable to thousands of submissions
- Reduced bias and improved fairness
Challenges and Trade-offs
- Accuracy vs latency trade-off
- Requires high-quality embeddings
- Needs tuning of HNSW parameters (efSearch, efConstruction)
Combining vector search with traditional filters creates the most reliable system.
Final Thoughts
Vector search is not just a feature—it is the foundation of modern AI recommendation systems. Algorithms like HNSW make it possible to search massive datasets in milliseconds while maintaining high accuracy.
PeerSubmit leverages this technology to deliver intelligent reviewer recommendations, transforming how academic conferences manage peer review at scale.
Start Running Your Conference—From Submission to Decision
Join hundreds of organizers who trust PeerSubmit to manage their academic events with AI-powered efficiency and seamless workflows.
No credit card required • Setup in minutes
Vector Search AI FAQs
Run Your Conference Without the Chaos
Manage submissions, peer review, registrations, and event workflows—all in one platform built for academic conferences.
Join hundreds of academic conferences already using PeerSubmitNo credit card required • Setup in minutes